Software at Scale
 Software at Scale
Software at Scale
Mitigate Connection Leaks in Production via Proxies
Every socket connection in Unix/Linux systems is represented by a file. Files opened by a process are represented by file descriptors - integer numbers that are used in I/O syscalls like read/write. By default, the per process limit for file descriptors for a user on Ubuntu is 1024 - which implies a process cannot have more than 1024 open files (or connections) simultaneously. This is a safe default so that any process cannot exhaust system wide limits, but it’s often set too low for servers that need to make a lot of connections, and the guidance is to bump this limit in many cases.
However, it’s easy to deploy a bug that leaks connections, causes the system to run out of file descriptors, and prevent new connections. Failures are often hard to debug, warrant their own war story blog posts, and happen across many different domains. By the nature of the problem, failures tend to occur only under load (in production) and are hard to reproduce in unit/integration tests. To make things worse, a connection leak in a large client can overwhelm a small service and cause downtime. For example, we might have a large monolith application that runs on a lot of nodes, and a tiny auxiliary service that runs on a few nodes. A leak in the monolith where it creates too many auxiliary clients might not trigger any alarms for the monolith, but will take down the auxiliary service.
It’s difficult to solve this problem in a truly general sense due to the various code paths that may have connection leaks. However, if we’re looking to solve only for internal service communication, we control internal RPC frameworks and deployments, and we can make it simple to debug these failures, catch them before full production rollout, and possibly eliminate them.
We describe some approaches that can be used in tandem to provide mitigations to this problem. Each approach has its own tradeoffs.
Singletons/Dependency Injection
One technique is purely related to code structure - to design RPC client creation in a manner where constructing multiple clients in the same thread is unidiomatic. One way to do this is to expose RPC client creation via a singleton pattern.
A simple implementation in Go might use Once - a struct that ensures a function runs at most once in a thread safe way - to provide an RPC client that’s shared across the process. It’s important to return a client that can automatically reconnect on connection failures/drops here.
// global vars
var rpcClientOnce sync.Once
var rpcClient rpc.Client
func MyRpcClient() {
rpcClientOnce.Do(constructRpcClient)
// now rpcClient will be non nil
return rpcClient
}
func constructRpcClient() {
// construct client here
rpcClient = ...
}Since singletons are often hard to mock out for tests, we can also use dependency injection, where RPC client classes (or a corresponding builder) is injected and cannot be instantiated manually after startup.
This approach doesn’t require any additional operational overhead, but might require extensive refactoring to work for an existing codebase, and doesn’t prevent all regressions. In practice, if the codebase convention is to use one of these approaches, then it’s likely that new callers will follow this pattern and avoid a leak.
Client Count Metrics
We can add a gauge that is incremented every time a new client is instantiated. These should be added to RPC client creation libraries so that new callers don’t have to explicitly opt into these metrics. This gives us instant visibility when we deploy a leak, since we can see the source of the leak via client metrics. Finally, if we have a canary analysis system like Kayenta, we can detect a large increase in connection count during canary compared to the baseline, and can stop a full rollout of a leak to production.
One downside of this approach is that we can’t set up simple alerts based on these metrics - often there’s no appropriate threshold to alert on, or we have to set up some convoluted alerts like client counts by node, and tweak it when we modify process count per node - which might happen when we modify node size. Another downside is that this might be flagged too late to prevent an outage. For example, a slow connection leak that happens on low traffic routes might not cause canary analysis to go off until after production rollout.
File Descriptor Count Alerts
We can use node exporters, like the Prometheus node exporter, to automatically monitor file descriptor count by node. This allows us to write a simple alert that can monitor used file descriptor percent by service/deployment. These can be combined with a rollout pipeline that validates alerts, for example, we can validate that <X% file descriptors are used on canary nodes before production rollout.
This has the same downside as analysis on connection counts - that slow leaks are hard to mitigate. But it’s independently useful, since file descriptors might leak for many other reasons and could cause downtime for a service, and a relevant alert will pinpoint the problem and speed up a mitigation.
Sidecar Processes
One common approach is to deploy a sidecar process on service node that performs all external RPCs on behalf of services on that node. Each external connection is made through the sidecar, so a connection leak in business logic will be de-duplicated at the sidecar layer and prevent connection overloads in another service. This sidecar can also set up a connection limit of one per client and upstream pair, so that failures can be localized to leaky processes, and errors will be debuggable. Sidecars can also expose metrics like connection counts, so that we don’t have to reimplement metrics collection in each language. Lyft seems to have followed a sidecar approach with Envoy.
This approach would remove the possibility of leaks causing an outage, but requires a global deployment of sidecar processes, and ensuring that communication only happens via sidecars, which is operationally expensive. Istio provides this architecture out of the box.
Addendum - Overloads due to Extremely Large Services
This section describes an uncommon but possible scenario where you have a service that’s so large (the monolith) that when it tries to make direct connections to a tiny auxiliary service, it overwhelms the service completely due to legitimate lack of file descriptors (not a leak). The author may or may not have seen an outage just like this.
The mitigation of the increasing number of nodes of the auxiliary service is inefficient and undesirable, since the problem could occur with the next tiny auxiliary service that has to answer to the monolith. One approach is that we can deploy sidecars with the auxiliary service and set up connection limits to protect each node. But it’s unclear what the connection limits should be, and how it should be configured, since clearly many nodes of a large client will need to connect to a single service in the usual case.
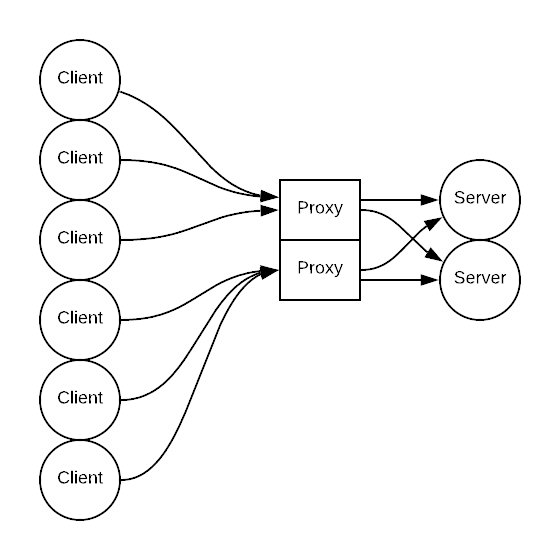
We can solve the problem by another layer of indirection - a proxy. We let services only communicate with each other through a proxy. Each proxy maintains connections with service nodes, and we prevent direct connections. This adds a few milliseconds of latency (1ms <= X < 5ms with Envoy in the same datacenter), adds a critical dependency and single point of failure, and is a lot of work to set up and maintain. But this also allows us to solve other problems that have good centralized solutions. For example, we no longer have to worry about connection pooling in application code, provide unified observability via an aggregated proxy dashboard, and set up request queues for admission control.
 a.image2.image-link.image2-560-560 {
padding-bottom: 100%;
padding-bottom: min(100%, 560px);
width: 100%;
height: 0;
}
a.image2.image-link.image2-560-560 img {
max-width: 560px;
max-height: 560px;
}
a.image2.image-link.image2-560-560 {
padding-bottom: 100%;
padding-bottom: min(100%, 560px);
width: 100%;
height: 0;
}
a.image2.image-link.image2-560-560 img {
max-width: 560px;
max-height: 560px;
}
Conclusion
In short, we can:
Structure our codebase to make it more difficult to create RPC clients on the fly
Monitor RPC client counts per service to try to detect a leak
Monitor used file descriptor percent of nodes per service to try to detect a leak
Deploy a sidecar process on each node to mitigate the effects of a leak
Connection leaks and overloads are a subtle but persistent problem that come with distributed systems/service architectures. There’s several overlapping solutions, but as with many things in Computer Science, a layer of indirection might help with a reliable, if more operationally expensive, solution.
Subscribe if you want to read more posts like these.




