Software at Scale
 Software at Scale
Software at Scale
Thoughts on API Reliability
Building and maintaining a public API is a unique software engineering challenge. We have to consider (roughly prioritized):
Security - exposing a service on the public internet has a variety of security implications - we want authentication/authorization as airtight as possible.
Reliability - the API is not useful if it’s down often.
Ease of use - it should be as frictionless as possible for developers to work with the API. Authentication flows, pagination, documentation should be as smooth and consistent as possible.
Stability - public API callers cannot change in lockstep with the internal codebase, so long term stability guarantees should be thought through.
Internal Developer Velocity - it should be simple for other developers in the organization to add new endpoints.
This is a vast and complex area, so I want to focus on one topic - API reliability. Once we want to consider our API generally available for a non-trivial set of users, we need to ensure it will stay reliable. In this post, we discuss common API reliability risks, mitigations, and a framework to keep our APIs reliable for the long term.
Reliability Risk Model
Just like security threat models, it’s useful to think about all the risks and potential scenarios that our API should be able to defend against.
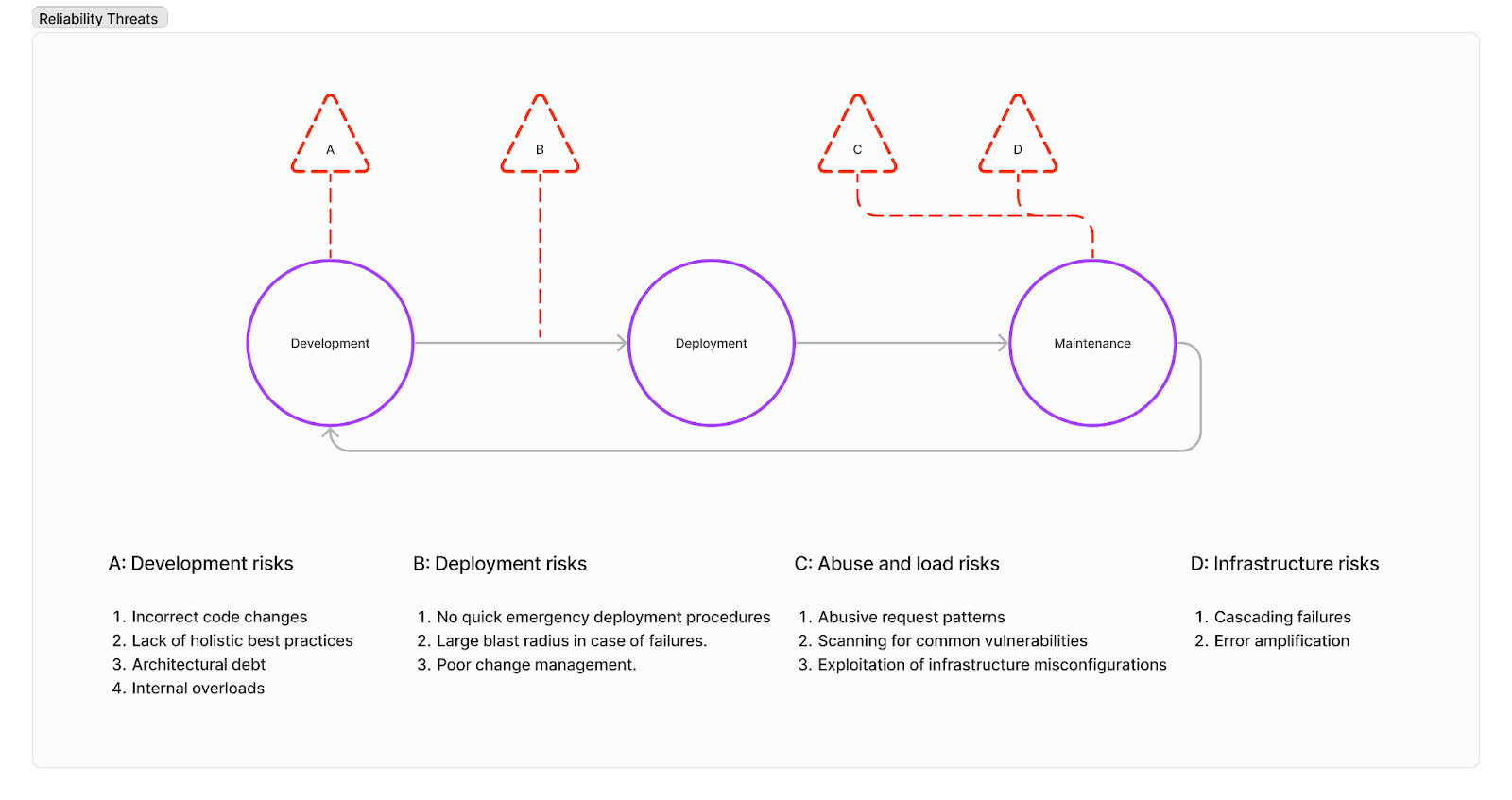
Breaking down risks into four categories:
Development risks: New faulty application code or infrastructure as code changes can lead to reliability issues. Additionally, application architecture and engineering practices also dictate ongoing reliability. For example, the right RPC library will enforce request timeouts and prevent overloads.
Deployment risks: The set of issues that prevent safe deployments. For example, the time it takes for a team to roll back a bad code change, and the likelihood that an on-call is empowered and trained to take a quick set of mitigations. There’s also the risk impact around faulty changes that can be tuned. For example, a faulty change might lead to a small availability impact to a canary environment, or a global outage, depending on our infrastructure and processes.
Abuse and load risks: APIs can go down even if there’s no changes going out due to changes in client behavior. Bad actors, and good but misconfigured clients are almost indistinguishable in most cases - and there’s a set of risks around abusive request patterns that have to be considered.
Infrastructure/dependency/operator risks: APIs are hosted somewhere, whether it may be a single machine in an office, or on thousands of cloud instances, and there’s physical infrastructure that might have issues. Alternatively, software infrastructure that our API depends on, like a caching layer, might fail and cause cascading issues.
Examples from my past experience/conversations:
Bad code deployments - new bugs/misconfigurations that take our API down.
Scanners that check for known vulnerabilities of common deployments. For example, Wordpress scanners that check if our admin site is publicly available. These might cause a large request volume.
Security scanners deployed by the company’s security team that perform the same operations as above, but are less concerned about getting rate limited/banned. So the request throughput may even be higher.
Cron jobs that make large bursts of requests on the hour that a service isn’t provisioned for.
Large bursts of requests when a particular resource goes viral (the HackerNews hug of death).
Large customers attempting a programmatic data-export/migration that cause database load due to hot keys/contention.
Extremely large customers performing unbounded API operations.
At one of my previous jobs, we had a concept of users and teams, and teams were generally not more than hundreds of users. But we signed up with a university, and they added forty thousand students to a one team. None of our features and APIs were designed for that sized team.
Internal services or batch jobs that overload a service that serves external requests.
A single bad host in a small deployment that causes a large availability hit due to error amplification.
For example, successful RPCs to the service generally take hundreds of milliseconds, but failures return almost instantaneously. Therefore, more requests get routed to the bad host since it has more capacity.
The website is down but the on-call engineer does not feel comfortable rolling back and is waiting for a 90 minute CI build for a forward fix to go out.
It’s worth coming up with a set of risks for our API, as it helps guide a set of principles to operate on and prioritize mitigations.
Mitigations
These are some common mitigations for various reliability risks.
Development Risks
Bounded operations
Our first observation is that most API defense measures like rate limiting, request quotas, and timeouts take place per operation. For example, rate limits are most often set up on requests per second. Therefore, we never want a single API operation to do unbounded work. Examples:
List operations should always be paginated.
Let’s say we have a ListUsers API call - this might be very cheap for small customers, but expensive for large customers - there’s increased database load, network bandwidth and serialization cost for the same operation. We have to tune the rate limit for our largest customers, which increases our developer friction.
In addition, the number of returned items have to be capped. Otherwise, pagination is not useful.
Set operations that need to operate on a list of items should always take a list of IDs.
And limit the number of items that can be operated on at a time.
This is likely the highest ROI principle to keep in mind - it’s easy to add more rate limiting infrastructure after the fact, but it’s hard to convert an unpaginated operation into a paginated one, because users will depend on older behavior.

Request timeouts
Low request timeouts are primarily an expectation setting mechanism and guardrail - if our API operations take too long, timeouts inform users that the operations have failed. If this happens sufficiently often, ideally, the API operator finds out about it through observability tools or support tickets, and can change the operation to do less work. It forces us to time-bound API operations. Ideally, the timeout also aborts the request so that the operation does not do any more work, but that’s often hard to implement correctly. For example, it’s really tricky to abort an ongoing request in Node. These little things are deeply considered in RPC libraries and implemented best by them - don’t roll your own request timeouts!
It’s very easy to bump up request timeouts as a cheap mitigation to a user perceived bug, but resist this temptation/schedule work to clean this up.
Deployment Risks
Change management
Once a faulty change has been rolled out, there needs to be a clear set of owners or DRIs who are trained or feel empowered to mitigate the issue. For business critical services, consider having an on-call rotation of engineers who are trained and equipped to drive mitigations.
Emergency rollbacks
For stateless services, a rollback is almost always the right approach to mitigate code change related outages. Rollbacks don’t need to go through the full test suite, as long as we can guarantee that service is being deployed at a change that was previously tested and deployed - which greatly helps with mitigation time.
API validation tests
A staging deployment that has no reliability bearings on the production deployment is a great test bed for risky changes and continuous API validation tests.
Canary deployments / Staged rollouts
After a certain scale, it’s worth considering a separate canary deployment which receives code changes before the rest of the fleet. This helps prevent large outages if a faulty code change hasn’t been tested well enough in other environments. A canary deployment has the advantage of being most similar to the production environment, so it helps testing changes in a more realistic scenario. More sophisticated setups may benefit from Canary Analysis.
A canary deployment has an unexpected benefit of being a load request playground and can help us understand our load limits. For example, by introducing a load balancer that automatically retries on 500s and spreads requests across canary and production deployments, we can afford to have a few requests to our canaries fail without impacting global availability. This lets us run experiments, like tuning down the number of canary replicas and see how our instances operate under load. This area is worth investing in if we run a high throughput, business critical service.
Additionally, larger, multi-region or stateful services should be deployed in stages to reduce the blast radius of faulty changes.
Separating live and batch traffic
With a service oriented architecture, it’s very simple to overload an externally facing, critical service with an internal batch job that needs to RPC to the service. Even worse, I’ve seen cases where mobile applications run end to end tests against the production service. The major downside here is that completely disabling such a workflow becomes infeasible over time, since other business critical parts of the system depend on the API.
It’s worth trying to completely separate traffic tiers, or even deployments, to prevent non-critical traffic from taking down our system. The Google SRE book has a good notion on criticality.
Abuse and load risks
Token limits
Simple limits can go a long way in helping with API reliability. For example, a limit on the number of API tokens created per user can prevent a malicious bot-farm from working around disabled/rate-limited API tokens.
Admin tools
Consider having an option to disable a misbehaving API key in an admin portal. This significantly reduces the amount of time it will take to mitigate an outage, and the on-call engineer will thank us for it. Having this ability to disable misbehaving API keys relies on having enough observability to know which clients are being the most troublesome. The simplest path is to have sampled logs on request counts, broken down by customer ID/user ID/hashed API token/token ID so we can find the offender easily.
Web Application Firewalls (WAFs)
WAFs (AWS, Cloudflare) are multi-purpose, and help with basic security posture as well as coarse rate limiting.
WAFs often let us set up rate limiting rules per IP address, and some even let us set up rules on request headers/bodies. They’re good at preventing misconfigured clients, scanners, and other tools from hitting our service at all, so that more sophisticated rate limiting only needs to be applied at another layer with lower request volumes. Another advantage is that they’re very cheap - AWS charges 60 cents per million requests + a flat fee, and in terms of engineering time - it’s very easy to add it in a cloud console/IaC. Finally, WAFs often have an option to manually block requests from an I.P. address, which can come in very handy during emergencies. Open source proxies like Envoy have enough configurability to enable WAF-like functionality, and may support holistic in-built ones some day.
A limitation of WAFs is that they only apply on small time frames, like “request count over the past five minutes”. So they won’t really help with cron-jobs with a greater than five minute cadence, and they’re completely useless for the first few minutes of an outage. Another issue is that many universities and corporate entities have a NAT gateway, which all requests through a single I.P. address. So over-aggressive WAF rules are certain to block legitimate traffic.
API Gateways
API Gateways are a nebulous topic. They provide a central point for our internal services with the external internet, for example, you can serve requests through different services for different routes on the same domain. For the purposes of reliability, they can be thought of as a layer of abstraction between the chaotic outside internet and internal systems. For example, if our setup will ever have more than a single service available over the external internet, we will have to think about the same measures - WAF, observability, timeouts, rate limits, for all such services. Whereas if all our services are protected by the gateway, then these defense measures only need to be set up once. And over time, as we might want to centralize other aspects, like authentication/authorization, and the gateway’s routing logic can be updated accordingly and without needing to duplicate this logic across several services.
In practice, API Gateways often provide rate limiting as well, so we don’t have to re-implement it in-house. They offer capabilities like canary deployments to reduce the blast radius of code deployments. So it’s worth considering whether to start an API architecture with a gateway.
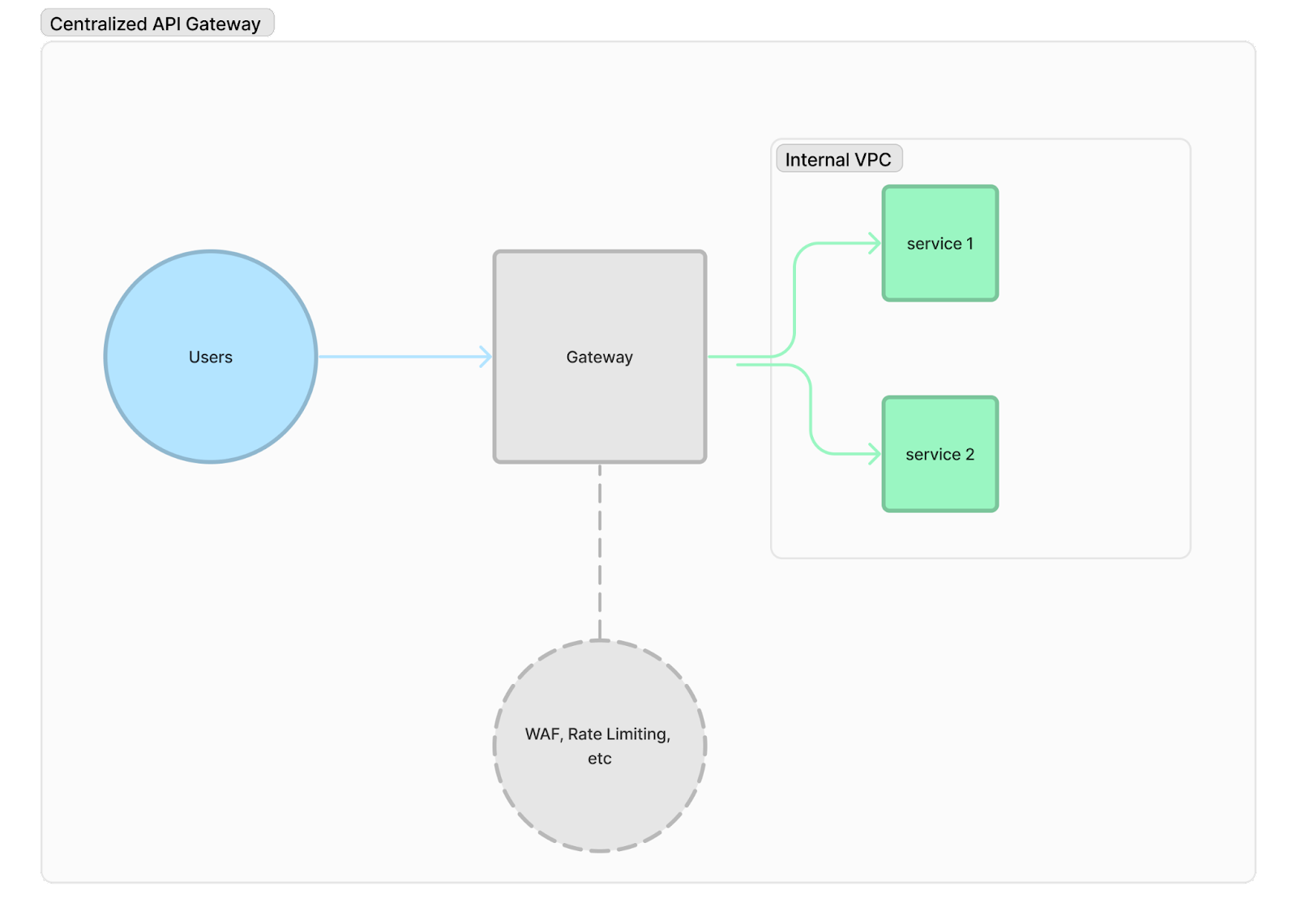
Rate limiting
The value proposition of rate limiting is fairly straightforward. The main question of rate limiting is always whether to fail open or fail closed.
If the rate limiter fails open - we have to consider the case where an abusive client causes the rate limiter to go down. We need to be vigilant about monitoring operational errors in the rate limiter, since it can silently be disabled, which might lead to an outage.
If it fails closed - we have to trust another infrastructure component with not degrading the availability of our API. For example, if our API has an availability SLA, then our rate limiter needs to meet or exceed that.
See the discussion on load testing below.
Auto-scaling
In a nutshell, auto-scaling means dynamically changing the number of replicas for a service based on a set of signals, like CPU utilization, request queue length, etc. Infrastructure platforms and orchestration frameworks often provide auto-scaling out of the box.
We have to be very careful to understand our systems before deploying auto-scaling. Let’s take the following barebones API architecture:
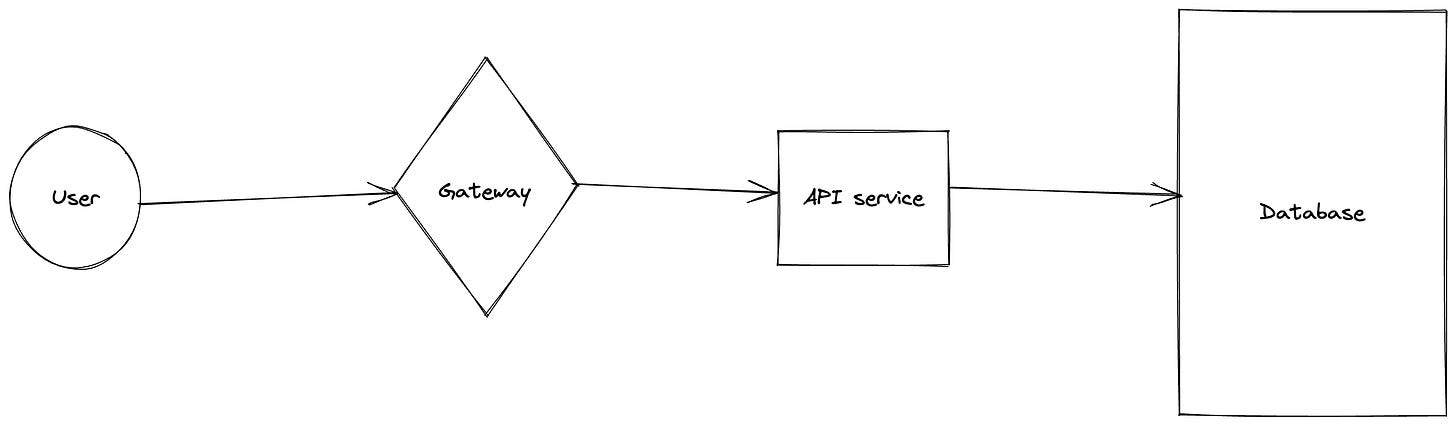
It might be simple to set up auto-scaling on the API service based on request latency. But that increases the number of concurrent requests to the database. If the database slows down due to increased load, that might lead to the auto-scaler adding even more API service replicas, which adds even more pressure to the database and might cause an outage. We expect this situation to happen whenever we’re I/O bound. This frequently happened at Heroku. Reactive auto-scaling should not be seen as a solution to malicious/abusive patterns, and more as a toil reduction measure for human operators, as well as a cost-saving measure for seasonal request loads. It is not an effective measure for sudden, borderline abusive changes in request throughput.
There’s also seasonal auto-scaling - preemptively scaling up instance counts during business hours or some other cadence due to a well known seasonal increases in load. This is generally more well understood, and a very reasonable approach.
Infrastructure / dependency risks
Outlier host detection
Given a sufficiently large number of instances running in a deployment, it’s very likely that a few instances will not be as performant as others. Cloud providers try to automatically replace or terminate poorly performing instances, but often, we have to do that work ourselves. That’s why, it may become relevant to set up monitoring for outliers and prevent requests reaching them. A poorly performing instance in a small deployment may cause error amplification if the instance fails requests much more quickly than a well-behaved instance processing successful requests.
Load testing
With a sufficiently complex architecture, it’s very hard to know how a system will perform under increased load. It’s worth understanding through synthetic load so that we know the system’s limits and can plan for future growth or seasonality of requests. Read this for a fascinating insight into load testing at Amazon.
Conclusion
To tie this up, an API developer has an array of things to consider to strengthen a public API. A suggested framework:
Come up with a reliability threat model to the API which produces a set of risks.
All APIs have to defend against scanners - this is a standard risk.
APIs that allow unauthenticated use have to defend against bots and abuse much more than ones that only allow authenticated use - so some risks are unique to our business and technical context.
Understand the impact of each risk - would the lack of defenses for the risk take down our entire site, or would the impact be limited to a single customer? These answers depend on our pre-existing software architecture. For example, if we have a single tenant architecture, the blast radius due to an abusive customer is much smaller.
Consider the mitigation speed for various risks, especially as they tie into your SLOs, as that will drive a discussion into remediation procedures.
With this input, we can come up with mitigations, a software architecture, and development principles and processes to keep our APIs reliable for a long time.
Credits
Thanks to Allan Reyes for reading early drafts of this post and providing excellent feedback!




